Visão geral
O sistema implementado para o IBOR Performance está organizado em uma infraestrutura separada que roda nos servidores da IBOR. Foram utilizadas diferentes tecnologias para a implementação das funcionalidades. Na imagem abaixo está uma visão geral de como está organizada essa arquitetura e como as partes se interagem. Ao longo dessa documentação as partes serão explicadas mais especificamente.

Mobile App
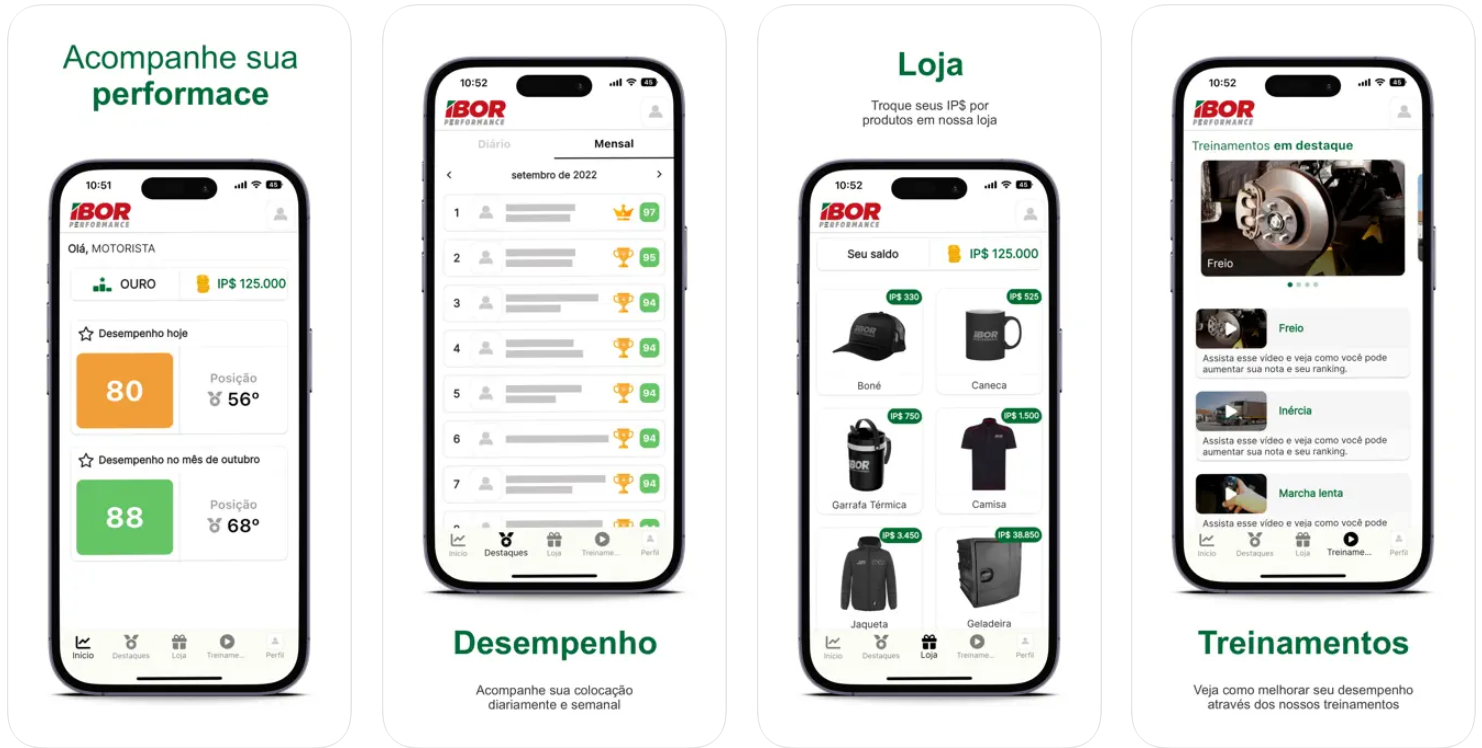
O app foi criado em Flutter utilizando a
linguagem Dart, atualmente está disponível na loja da
Google Play
Store e
na App Store. O
código do projeto está disponível no repositório
https://github.com/ibortransporte/app.
Painel Admin
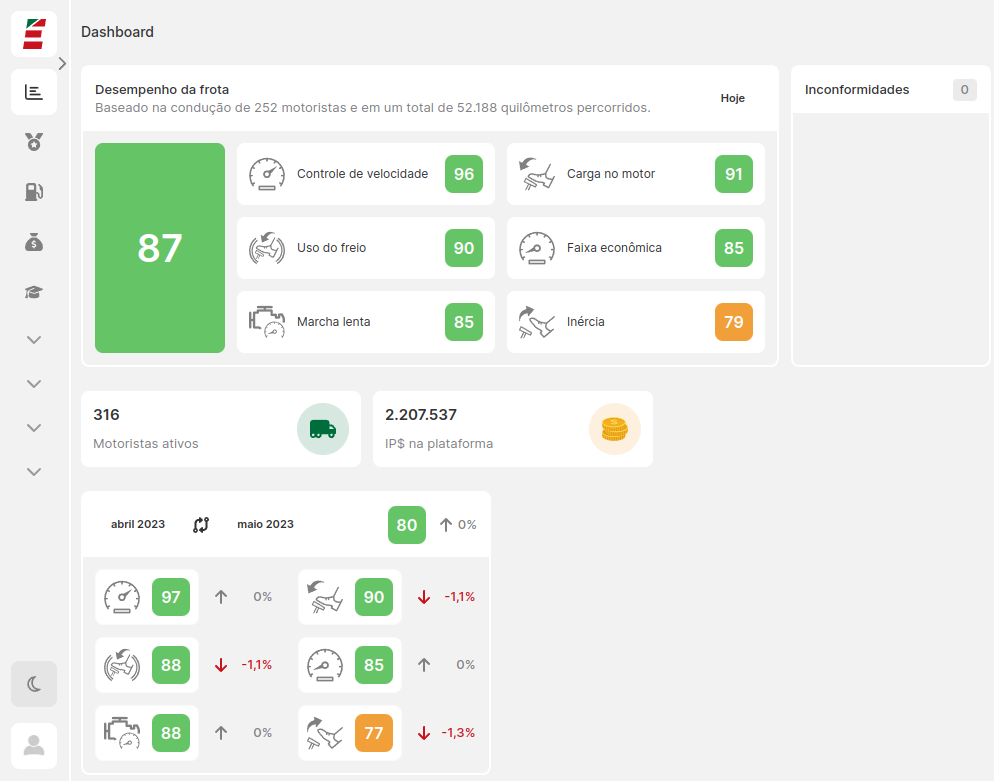
A versão mais atual do painel admin foi feita em React e
está online no link
https://performance.ibor.com.br o código do
projeto está disponível no repositório
https://github.com/ibortransporte/dev-panel.
A primeira versão do painel admin foi feita em Vue e não
está mais online. O código está do projeto está no repositório
https://github.com/ibortransporte/panel.
Nossa Infraestrutura
A infraestrutura necessária para executar o projeto está configurada no
repositório
https://github.com/ibortransporte/infra.
A maioria das configurações necessárias estão no arquivo docker-compose.yaml
que "orquestra" os containers necessários para o projeto. Além disso, há também
a configuração do Caddyfile que configura os endpoints/domínios que serão
direcionados com HTTPS.
NOTA: Para a configuração correta do ambiente é necessário criar um arquivo
.envcom as devidas variáveis de ambiente. Um template mínimo está disponível no arquivo.env.dev.
É possível identificar que o arquivo docker-compose.yaml possui mais
containers do que os mostrados na imagem de visão geral. Isso porque, alguns
containers fornecem funcionalidades "pequenas", mas que ainda assim serão
comentadas nas próximas seções.
Hasura API
Utilizamos o Hasura para acelerar o processo de
desenvolvimento, ele é responsável por gerar schema e resolvers para o
acesso ao banco de dados e outros por meio do GraphQL
tendo a vantagem de poder criar as queries GraphQL tanto no app
quanto no painel sem ter que modificar o backend. Além disso, o
Hasura possui um sistema próprio de autorização, o que facilita a criação de
permissões para acesso à dados/funções para diferentes tipos de usuários
(motorista/admin/instrutor). Ele também é responsável pelo controle de eventos
periódicos do projeto. Isto é, atualizações periódicas como a atualização dos
motoristas ou do ranking são chamadas por cron triggers configuradas no
Hasura, assim como notificações que são enviadas automaticamente com um insert
por meio de event triggers.
OBS: O
Hasuraapenas realiza as chamadas, mas o processamento dos eventos é feito nas determinadas apis.
Atualmente o Hasura está sendo executado no link
https://hs.ibor.com.br/
metadata/migrations estão no repositório
https://github.com/ibortransporte/hs.metadata: Configurações próprias doHasuratais como tabelas trackeadas, actions, events, ...migrations: Queries para aplicar/reverter migrações específicas de cada banco de dados.
Banco de dados
O banco de dados utilizado foi o Postgres por
ser open source e possuir boa performance, além da boa integração com o
Hasura. As informações necessárias para configurar o schema estão no
repositório do Hasura na pasta migrations/default.
O banco está dividido principalmente em 2 schemas um sendo o public que possui
todas as tabelas criadas para o domínio específico e outro empty_tables que
foi criado para criar tabelas vazias que servem para o Postgres identificar
tipos corretos de retorno para stored procedures. Além disso, outro schema
deve ser criado futuramente para a melhor separação de stored
procedures/triggers que hoje estão no schema public.
OBS: O
Hasuraarmazena informações de migração, cron, eventos dentro de um schema próprio nomeadohdb_catalog. Caso indexes ou tabelas desse schema cresçam muito (improvável) é possível deletar dados desnecessários, para isso siga esse link.
API Node
Uma API foi construída para complementar as funcionalidades providas pelo
Hasura, ela foi criada em Node utilizando
Typescript. As principais funcionalidades
implementadas são: autenticação, upload de arquivos, processamento do ranking e
processamento de dados para gráficos. Atualmente a api está disponível online no
link https://api-app.ibor.com.br/.
AWS
Por praticidade alguns serviços da Amazon estão sendo utilizados para o
funcionamento do sistema.
AWS S3
O Amazon S3 foi utilizado para armazenamento
dos arquivos relacionados a esse sistema, isso porque, ele possui baixo custo e
alta disponibilidade. Atualmente o bucket utilizado é o files-ibor.
Monitoramento externo
O monitoramento externo foi feito por meio do Grafana
que possibilita a criação rápida de dashboards para monitoramento, em conjunto
com o Prometheus para o armazenamento e
processamento de dados de séries temporais (métricas, status, performance ao
passar do tempo). O dashboard está sendo hospedado em uma máquina no Amazon
EC2, isso por causa do baixo custo e por estar
fora da arquitetura do sistema. Isso é bom tendo em vista que caso a
infraestrutura fique fora do ar, ainda será possível identificar/analisar as
métricas disponíveis no dashboard.
IBOR Infraestrutura
Nessa infraestrutura pouco foi alterado, esta seção está aqui mais para descrever o que foi utilizado da infraestrutura da IBOR já existente.
SQL Server
O banco de dados utilizado é o SQL Server com diversos databases e tabelas
já existentes. Para esse sistemas os databases mais utilizados foram:
SGIBOR, infra, VOLVO e GEOPROCESSAMENTO. Pelo nosso sistema o banco é
acessado apenas pela API Node (Hasura não acessa diretamente
esse banco).
notas-veiculos-ibor
A API notas-veiculos-ibor foi criada em Java
e é responsável por prover para a API Node as notas de condução
dos motoristas por um determinado período de tempo, com esses dados é possível
processar o ranking dos motoristas diariamente/mensalmente.